
突发奇想,给自己的 beancount-bot 接入了多语言支持。本文简单记录了接入和使用的流程。
在很久很久以前,我曾经在 Django 中使用过多语言支持,但还未尝试过使用底层框架为任意项目提供多语言支持。正巧昨天想将最近开源的 beancount-bot 推荐给 awesome-beancount 项目,而之前的所有文本几乎都是用中文写的。于是,我打算为它提供多语言支持,顺便学习一下 gettext.
背景
在企业中,我们通常将涉及到多语言的工作称为“国际化”工作,但提到相关领域,我们通常绕不开两个意思相近的词:国际化(internationalization,缩写为 i18n)和本地化(localization,缩写为 l10n)。
按照我的理解,国际化工作更偏向框架层面,旨在为程序提供支持多语言的能力;而本地化工作更偏向是细节层面,其目标是在已有的国际化框架中,通过翻译等手段来提供得体的、符合当地文化环境的内容。
GNU gettext 的文档 更详细地介绍了这两个概念的区别。
除了我们熟悉的文本翻译以外,货币、日期、数字表示法甚至 RTL 也属于国际化的工作范畴,这篇文档中详细介绍了更多国际化的工作内容。
在 Python 和 C 语言的程序中,我们通常会使用 GNU gettext 工具包来完成多语言支持工作。它提供了简洁且易于使用的框架,可以让开发者以极其微小的成本为程序来提供国际化支持。
而 Python 也提供了对应的 gettext 包来支持相关工作。
语言(language)和地区(locale)
在国际化工作中,“语言”(language)和“地区”(locale)是两个核心概念,它们在定义应用程序或内容如何适应不同市场和用户需求时扮演着关键角色。
语言指的是人们用于交流的符号系统,如英语、汉语、西班牙语等。它主要关注文本的翻译和语言习惯的适应,确保内容在不同语言环境下的可理解性和自然性。
地区则是一个更广泛的概念,它不仅包括语言,还涵盖了与特定地理区域相关的所有文化、法律和格式规范。这包括日期和时间的显示格式、货币符号、数字格式、排序规则等。地区设置确保了应用程序在不同地区的用户界面和功能能够符合当地的文化和习惯。
比如,我们在安装系统时,通常会有一个提示界面让我们去选择“语言和地区”。如果用户选择了“英语(美国)”作为他们的地区设置,那么应用程序应该显示美式英语的文本,使用美元符号($)作为货币单位,并按照美国习惯格式化日期(如 MM/DD/YYYY);而如果用户选择了“英语(英国)”,虽然语言同样是英语,但日期格式(如 DD/MM/YYYY)和货币单位(£)将会有所不同,以适应英国地区的规范。
在 POSIX 系统中,我们通常会使用 语言代码_地区代码 的格式来表示 locale. 比如上面的两个 locale 的代码分别为 en_US 和 en_GB.
通过精确区分和应用这两个概念,国际化工作能够确保软件产品和内容在全球范围内的有效性和用户满意度。
接入流程
通常情况下,一个 Python 程序接入多语言的工作流程如下图:
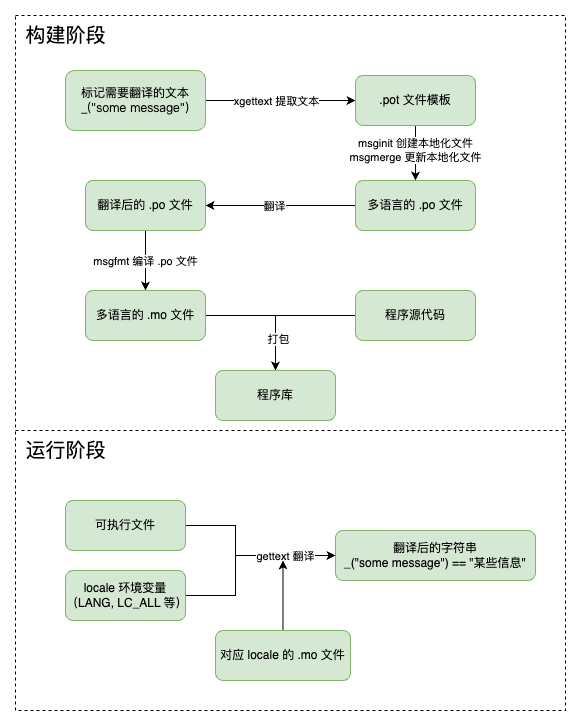
在 gettext 中,我们会通过 msgid 来对文本做唯一标注,而这个 msgid 的值就来自于源代码中在 _ 函数做参数的字符串。然而,在不同的语境中,同一个单词会具有不同的含义,如 position 一词可以表示“位置”,也可以表示“头寸”。
为了隔离不同的使用场景,gettext 创造了“域”的概念,并通过文件来将不同域的本地化配置隔离开来。在后文中,我们会假设使用的域为 mydomain。
具体的操作步骤如下:
- 在 Python 代码中先通过
gettext.gettext函数(通常会使用_做别名)来标记所有需要翻译的字符串。
需要注意的是,需要翻译的字符串必须是“静态”字符串,而不能是f-string这种内容不确定的字符串。如果需要动态生成,可以考虑用format或%函数来渲染翻译后的字符串。 - 标记好后,通过
xgettext -d mydomain -o locale/mydomain.pot **/*.py扫描源代码中的字符串,并生成.pot本地化模板; - 选择你期望翻译的 locale,假设为
zh_CN,并根据翻译模板生成.po本地化文件:- 如果是初次生成,则运行
msginit -i locale/mydomain.pot -o locale/zh_CN/LC_MESSAGES/mydomain.po -l zh_CN; - 如果要更新现有
.po的内容,并保留之前已完成的翻译结果,则运行msgmerge --update locale/zh_CN/LC_MESSAGES/mydomain.po locale/mydomain.pot
- 如果是初次生成,则运行
- 打开
.po文件,并翻译现有内容(我选择了直接扔给 LLM,让它翻译之后按原格式输出)
如果是内容更新,最好特别留意包含fuzzy标签的翻译记录;fuzzy的具体含义可以参考文档。 - 翻译之后,运行
msgfmt -o locale/zh_CN/LC_MESSAGES/mydomain.mo locale/zh_CN/LC_MESSAGES/mydomain.po将.po编译成机器识别的.mo格式。
我将以上流程整理成了一个 Makefile,这样只需要 make all 即可完成增量构建。
1 | LANGUAGES := en zh_CN zh_TW fr_FR ja_JP ko_KR de_DE es_ES |
运行时翻译
在完成上面的国际化流程后,我们就可以运行我们的程序来对代码内的文本进行翻译了。
我们可以使用以下代码来初始化多语言环境:
1 | locale_dir = pathlib.Path(__file__).parent / 'locale' |
注意,此处本地化文件的目录传递了绝对路径。如果只写 locale 作为目录,则 gettext 会以当前的工作目录为基准去查找本地化文件,而这很可能导致翻译功能失效。
在默认情况下,gettext 包会按顺序读取环境变量(LANGUAGE, LC_ALL, LC_MESSAGES, LANG),并从中找到用户的偏好 locale;若这些变量均为空,则会降级到 C locale.
在确认目标 locale 后,我们在代码中调用 _ 函数时,它就可以将源字符串转换为翻译后的字符串。
关于刚刚提到的几个环境变量,它们的关系说来复杂,如果读者有兴趣,可以阅读 GNU gettext 文档中的 《设置 POSIX locale》 部分。
显式指定 locale
虽然我们的默认 shell 环境中都包含了 locale 相关的环境变量,但在某些环境(如容器)里,这些环境变量是不会设置的。
除了通过 -e 参数注入环境变量外,或许我们还可以考虑通过配置文件等方式为程序显式指定所用的 locale。
此处有两种方法:
- 环境变量覆盖:通过
os.environ['LANGUAGE'] = "ll_CC"的方式,来为全局的 gettext 函数指定语言; - 局部翻译变量:使用
translation = gettext.translation("mydomain", locale_dir, ["ll_CC"], fallback=False)生成一个独立的翻译对象,并将translation.gettext作为_函数来生成翻译文本。
参考文档
- GNU gettext 文档
- Python gettext 文档
- 通过 Deepseek 快速上手
gettext接入流程 - 通过
Claude 3.5 Sonnet完成了Makefile的重构