Service 自带负载均衡,所以如果 Service 背后的 Endpoint 有多个,那么多次抓取的数据来源则可能是 Serivce 背后的任意一个 Pod,而且我们也无法对来源进行区分。因此,当我们分析业务指标时,通常都会通过服务发现来抓取所有 Pod 的指标,然后通过 PromQL 根据实际场景对指标进行聚合。
假设 K8S API 地址为 https://k3s:6443,那么当我们想访问 Service proxy 时,就可以通过 https://k3s:6443/api/v1/namespaces/<namespace>/services/<service_name>[:<service_port>]/proxy/metrics 来获取。
相应地,抓取 Pod 指标时,对应的 API 地址为 https://k8s:6443/api/v1/namespaces/<namespace>/pods/<pod_name>[:<pod_port>]/proxy/metrics
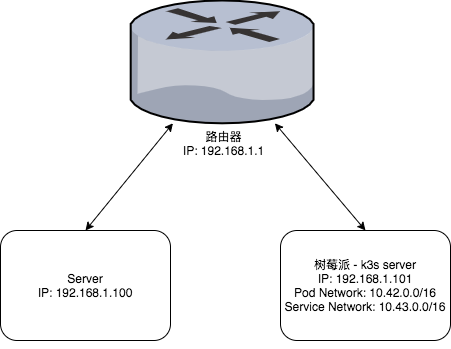
ip route add 10.42.0.0/16 via 192.168.1.101 dev enp1s0 ip route add 10.43.0.0/16 via 192.168.1.101 dev enp1s0
如果想要在局域网内打通的话,可以在路由器的管理后台来配置静态路由规则;如果集群存在多个节点,则还需在 Node 的 iptables 中配置 MASQUERADE 规则用于转发。
配置完成后,Prometheus 就可以直接通过 Pod IP 或 Service 的 Cluster IP 来抓取指标了。
之前通过 Argo CD 安装脚本 在集群内安装了 Argo CD. 当我配完上面的规则以后,我发现 argocd-metrics Service 的指标无法通过 Cluster IP 抓取(报错”Connection refused“),而 argocd-server-metrics 就可以。而在 Node 上,两个服务均可以正常访问。
查了 Node 上的 iptables 规则,没有在 Service (argocd-metrics) 到 Pod (argocd-application-controller-0) 的转发链路中发现任何异常,直接访问 Pod IP 也验证了这一点。
但由于缺乏 iptables debug 经验,并没有找到访问 Pod IP 被拒绝的原因。
# Service -> Pod with DNAT -A KUBE-SERVICES -d 10.43.4.242/32 -p tcp -m tcp --dport 8082 -m comment --comment "argocd/argocd-metrics:metrics cluster IP" -j KUBE-SVC-SZWGFJCG7JW62ZG2 -A KUBE-SVC-SZWGFJCG7JW62ZG2 -m comment --comment "argocd/argocd-metrics:metrics" -j KUBE-SEP-VYRHUQXWRJ6MSGOH -A KUBE-SEP-VYRHUQXWRJ6MSGOH -p tcp -m tcp -m comment --comment "argocd/argocd-metrics:metrics" -j DNAT --to-destination 10.42.0.38:8082
# Pod 转发至 pod 防火墙 -A KUBE-ROUTER-OUTPUT -d 10.42.0.38/32 -m comment --comment "rule to jump traffic destined to POD name:argocd-application-controller-0 namespace: argocd to chain KUBE-POD-FW-XIOATVM5TOINSO4V" -j KUBE-POD-FW-XIOATVM5TOINSO4V
-A KUBE-POD-FW-XIOATVM5TOINSO4V -m conntrack --ctstate RELATED,ESTABLISHED -m comment --comment "rule for stateful firewall for pod" -j ACCEPT # 通过 local mode (也就是从 node ip) 访问 pod 的包都会被批准 -A KUBE-POD-FW-XIOATVM5TOINSO4V -d 10.42.0.38/32 -m addrtype --src-type LOCAL -m comment --comment "rule to permit the traffic traffic to pods when source is the pod\'s local node" -j ACCEPT # 接受 argocd-application-controller-network-policy 的规则判断,通过后会被打上标记 -A KUBE-POD-FW-XIOATVM5TOINSO4V -m comment --comment "run through nw policy argocd-application-controller-network-policy" -j KUBE-NWPLCY-5VLCZNPWIAXAL2HB -A KUBE-POD-FW-XIOATVM5TOINSO4V -m mark ! --mark 0x10000/0x10000 -m limit --limit 10/min --limit-burst 10 -m comment --comment "rule to log dropped traffic POD name:argocd-application-controller-0 namespace: argocd" -j NFLOG --nflog-group 100 # 没有标记(没通过规则判断),就会拒绝连接 -A KUBE-POD-FW-XIOATVM5TOINSO4V -m mark ! --mark 0x10000/0x10000 -m comment --comment "rule to REJECT traffic destined for POD name:argocd-application-controller-0 namespace: argocd" -j REJECT --reject-with icmp-port-unreachable
# 第一条 namespaceSelector 规则,对应 8082 端口 # namespaceSelector: {} # 满足条件则会打上标记,然后 return -A KUBE-NWPLCY-5VLCZNPWIAXAL2HB -p tcp -m set --match-set KUBE-SRC-DRBIHPAD4OLOF546 src -m set --match-set KUBE-DST-DM6ZQPCTKCXEROGZ dst -m tcp --dport 8082 -m comment --comment "rule to mark traffic matching a network policy" -m comment --comment "rule to ACCEPT traffic from source pods to dest pods selected by policy name argocd-application-controller-network-policy namespace argocd" -j MARK --set-xmark 0x10000/0x10000 -A KUBE-NWPLCY-5VLCZNPWIAXAL2HB -p tcp -m set --match-set KUBE-SRC-DRBIHPAD4OLOF546 src -m set --match-set KUBE-DST-DM6ZQPCTKCXEROGZ dst -m tcp --dport 8082 -m comment --comment "rule to RETURN traffic matching a network policy" -m mark --mark 0x10000/0x10000 -m comment --comment "rule to ACCEPT traffic from source pods to dest pods selected by policy name argocd-application-controller-network-policy namespace argocd" -j RETURN
# 自己加上去的第二条 ipBlock cidr 规则,8082 端口 # ipBlock: # cidr: 192.168.1.0/24 -A KUBE-NWPLCY-5VLCZNPWIAXAL2HB -p tcp -m set --match-set KUBE-SRC-MLGAJX4FU64MJPWH src -m set --match-set KUBE-DST-DM6ZQPCTKCXEROGZ dst -m tcp --dport 8082 -m comment --comment "rule to mark traffic matching a network policy" -m comment --comment "rule to ACCEPT traffic from specified ipBlocks to dest pods selected by policy name: argocd-application-controller-network-policy namespace argocd" -j MARK --set-xmark 0x10000/0x10000 -A KUBE-NWPLCY-5VLCZNPWIAXAL2HB -p tcp -m set --match-set KUBE-SRC-MLGAJX4FU64MJPWH src -m set --match-set KUBE-DST-DM6ZQPCTKCXEROGZ dst -m tcp --dport 8082 -m comment --comment "rule to RETURN traffic matching a network policy" -m mark --mark 0x10000/0x10000 -m comment --comment "rule to ACCEPT traffic from specified ipBlocks to dest pods selected by policy name: argocd-application-controller-network-policy namespace argocd" -j RETURN